


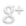

In a brilliant and hilarious article Zeller, Zimmerman and Bird points out how easy it is to find correlations when mining software archives. In the article, their (mock) argument is that all program errors must enter the source code through the keyboard and thus certain keys introduce more errors. By statistical analysis of the Eclipse 3.0 source code they are able to determine that the keys IROP are extra error prone and that programmers should avoid the IROP keys!
No really, it’s not true that programmers should avoid the IROP keys

Using the IROP keyboard will not reduce errors in Eclipse code by 73%!
They then move on to explain why this kind of research is fundamentally flawed. Yet, we see a lot of it everywhere… Not just in SBSE and related fields. I liked this article because it made me question my own work on correlation based regression test selection. But then, it is based on an algorithm by Zimmerman et al so should be free of at least this error.
Interestingly enough and in the same alert from Google Scholar, I find two articles, where the authors have performed correlational studies to determine fault prone features of software. Krishnan et al. and Bell, Ostrand and Weyukur have both determined that the level of change in a software artefact is a good predictor of fault proneness. What to make of that? I think there are at least three reasons for the finding:
- Software testers work based on the same requirement delta as developers thus writing test cases for the same code as the programmers are testing, so if they do their job properly they should find errors in exactly the changed code.
- Already tested and released code should have been thoroughly tested and thus not contain additional errors, at least not error that are found by the existing test cases which have already passed. Unless of course there is already a bug report and then that code would be changed again.
- It is much more likely that you break the code by changing it rather than by not changing it, even though the latter is certainly also possible.
So how interesting are these results? How actionable are they?
References
[bibtex file=http://www.citeulike.org/bibtex/user/greger/tag/20111003-irop?fieldmap=posted-at:posted-date&clean_urls=0]
Image sources
- IROP keyboard: Thomas Zimmermann







This article http://www.technologyreview.com/computing/38775/ is just another example of scientists warning aboutcorrelation and data mining studies from large data sets.
As always, there is a Dilbert strip for this http://www.dilbert.com/strips/comic/2011-11-28/ .
Pingback: Agile Project Manager » Blog Archive » Agile Developers Trust their Teams